

The Performance Paradox: Why Low CPU Usage Can Be a Red Flag
- Anatoliy Medvedchuk

- Jan 27
- 4 min read
Updated: Jan 30
As of 2025, roughly 40% of enterprise systems were beyond end of life or support, with decade-old libraries hiding under the hood. Everything looks stable on the surface, while a critical failure brews underneath.
Our team recently tackled a case where standard monitoring tools proved useless. We’ve decided to share this investigation so you know exactly where to look when everything is 'green,' but nothing is working.
When the system goes into “digital shutdown”
The anomaly followed a frustratingly consistent pattern: the system would run smoothly for about 90 minutes, only to “flatline” for the next 10 to 20 minutes. During these blackouts, the API simply stopped responding to client requests.
On the surface, the infrastructure was idling. Our monitoring showed CPU and Memory stayed well within healthy limits. The hardware was “resting” while the business was hemorrhaging transactions.
We were facing a classic case where infrastructure metrics provide only a “hospital average temperature,” completely ignoring internal application-level locks.
API activity drop
The investigation: tracing locked threads
The architecture under fire was a standard but complex stack:
WSO2 API Manager + WSO2 Identity Server (IS) → Business Services
Our deep dive began with JMX and JVisualVM analysis of the API Manager. While RAM and CPU looked fine, we discovered that Java threads were massively transitioning into a waiting state during socket reads (SocketInputStream.socketRead0).
A quick check of active connections via netstat confirmed our suspicion:
The API Manager was stuck waiting for a response from the WSO2 Identity Server.
The trail led us to the Identity Server, where thread dumps finally revealed the smoking gun. We hit a massive bottleneck. Threads were piling up, blocked on a Java monitor during class loading: java.lang.ClassLoader.loadClass — locked

Threads blocking
The root cause: the Axis2 serialization trap
The culprit was the Axis2 library (specifically the BeanUtil.getBeanInfo method).
Due to a complete lack of caching, every time the system performed object serialization, it attempted to reload class information from scratch. It triggered a synchronized block that paralyzed all other threads.
To make matters worse, we had a "perfect storm" scenario: the thread pool had a short TTL (Time-To-Live). Each new iteration of thread creation triggered a fresh wave of class-loading attempts, creating a feedback loop that eventually choked the system into a total standstill.
Our rescue strategy
Once the diagnosis was confirmed, we faced a difficult choice: follow standard protocols or resort to emergency resuscitation. Our team evaluated three potential scenarios, each with its own costs and risks:
The canonical path: full upgrade
The most obvious solution was to upgrade the entire WSO2 stack to current versions where the vendor had already patched this issue.
Verdict: Rejected.
Reason: Due to deep system customization, this process would have taken a long time. The business could not afford to wait that long while the system continued to flatline every 90 minutes. We moved this option to the strategic transformation roadmap, but it was not a viable solution for immediate fire suppression.
Tuning and dependency hack: seeking a "lesser evil"
We attempted to increase the Thread TTL in the pool to reduce the frequency of lock triggers. Simultaneously, we tried to swap in a newer version of the Axis2 library independently of the core system.
Verdict: Failure.
Reason: Increasing the TTL only slightly delayed the crashes, but didn't eliminate them. As for the library swap, we immediately hit “dependency hell”: a cascade of conflicts where the legacy components of the system proved fundamentally incompatible with the new dependencies.
Custom patch: engineering "guerilla tactics"
Realizing that standard methods were powerless, we took a step you won’t find in clean code textbooks. We strictly recommend not to “try it at home” unless you are 100% confident in your actions.
Our team executed a Custom Patch. We tracked down the source code for the exact legacy version of Axis2 running in the system and manually integrated a caching mechanism, essentially backporting a fix from future releases. Then specialists compiled our own JAR file and "hot-swapped" it into the system.
Does this look like a “dirty hack”? Perhaps. But when the business is paralyzed and standard procedures fail, an engineer has the right to be bold: provided that boldness is backed by a deep understanding of internal JVM processes.
Verdict: Success.
The Result: System lift-off
The outcome
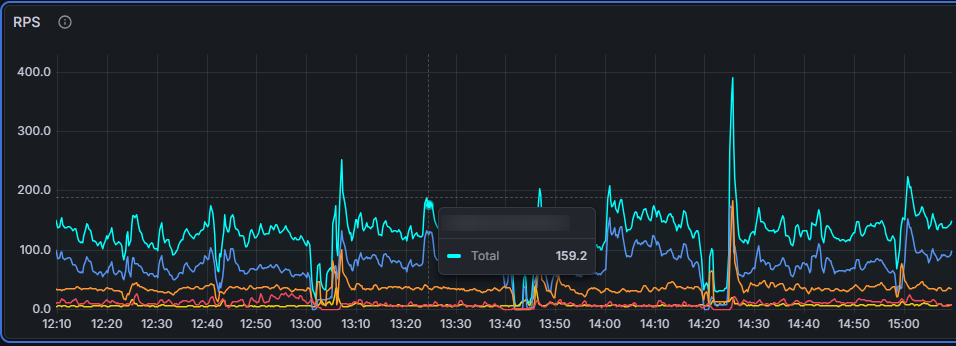
Immediately following the deployment of our custom build, the behavior changed. The cyclical crashes that had plagued the system vanished. The Java monitor locks disappeared, RPS stabilized, and response times finally became predictable.
We made this move deliberately. In an ideal software world, this isn't how things are done. But in the real world, a surgical "hack" is sometimes the only way to save the business here and now, buying the time needed for a strategic upgrade.

Seamless operation after Custom Patch
Key takeaways: lessons worth sharing
Resource monitoring vs. business metrics
If your CPU is idling at 10% while your RPS is plummeting, you likely have a concurrency issue. Never rely solely on "green" memory charts. The true health of a system is measured by end-to-end latency and throughput.
The importance of deep visibility
System transparency lies in understanding thread pool states, open network connections, and the response times of every microservice in the stack. Without it, you are flying blind.
Technical debt as a failure risk
Timely Lifecycle Management and digital transformation are insurance against time-consuming fixes and lost revenue. Outdated software can trigger a denial of service even on the most powerful hardware.
The legacy tax
You pay for outdated libraries through a lack of features and performance degradation that cannot be fixed by "throwing more hardware" at the problem.
Balancing best practices with business reality
Sometimes a “dirty” hotfix is the only way to save the business at the moment. It buys you the time needed for a strategic upgrade. The key is to strictly document it as technical debt and have a clear repayment plan.
System correlation
A failure in one node (Identity Server) often manifests as a problem in another (API Manager). Without end-to-end Observability, you will spend your time treating symptoms rather than curing the disease.


